前言
在 JVM 内存结构 中,我们说到,当 JVM 执行 new 指令为对象分配内存时,会在堆中申请一块内存;而这块内存的回收,便是由垃圾收集器负责的;实际上,不只是垃圾回收,对象的内存分配,也取决于当前使用的垃圾收集器类型,这点也好理解,比如我将内存分代了,那新分配的内存一般都是在新生代分配,而不是在老年代分配。
一个 JVM 可能同时会使用多个垃圾收集器,我们讨论回收策略的时候,其实是在讨论某一款 垃圾收集器 的策略,而不是在讨论某款 虚拟机 的策略。
所有的垃圾收集器要解决的问题,都可以概括成两个:怎么判断对象可以被回收、怎么回收这些垃圾对象。
下面,我们就从这两个问题入手,理解垃圾收集器的工作原理。
标记
首先看一下垃圾收集器怎么判断一个对象可不可以被回收。
我们可以认为,如果我们在代码中,无法再通过任何形式去使用到这个对象,那么这个对象对我们而言就是垃圾对象,可以被回收了。
判断一个对象还会不会被使用,主要有两种方法:引用计数法和可达性分析法。
引用计数
引用计数法很好理解,就是每个对象都记录还有多少个对象引用了自己。如果已经是 0 了,说明没有任何对象在引用自己了,那么这个对象就可以被回收了。
C++ 11 里的智能指针就是使用了这个方法,当该智能指针被赋值时,内部的引用数就加一,当该智能指针被析构时,内部的引用数就减一,直到减为 0 时,便释放内存。
引用计数法会带来 循环引用 的问题。比如 A 和 B 两个对象互相引用,即使他们实际上已经可回收了,但由于两个对象的被引用数都不为 0,因此两个对象都无法被回收。使用 C++ 的智能指针也会引起这个问题,要解决这个问题,我们经常要将其中一个引用改为弱引用。
可达性分析
引用计数法虽然简单,但还是要处理很多额外的情况,所以几乎所有的 JVM 垃圾收集器都是使用 可达性分析法 来判断对象是否存活的。
可达性分析法就是从引用的源头开始遍历引用图的方法。首先,我们先找到那些绝对不可以被回收的对象,比如局部变量(如果局部变量被回收了,那这个方法还怎么执行呢)、类静态变量、方法区中的常量等;然后,以这些绝对不可以被回收的对象为起点,我们需要找到所有被他们引用、或者被他们引用的对象所引用 的对象,这些能被遍历到的对象,都是不可以回收的,因为我们完全可以在代码中访问到这些对象;最后,剩下没有被遍历到的对象,我们就可以认为他们是可以被回收的垃圾对象了。
仔细想想,这些引用关系所构成的,正是一个有向图的结构;因此,遍历这些对象,实际上就是遍历图。
JVM 垃圾收集器基本都采用 三色标记法 来进行引用图的遍历,也就是对象的标记,因为这个方法可以用来支持并发标记,下面我们就来介绍一下这个算法。
三色标记法
三色标记法将图的节点分为三个状态:白色(未开始标记)、灰色(已经开始但没标记完所有子节点)、黑色(所有子节点都已经标记结束)。
初始时,所有的节点都是白色;一旦进入一个节点,该节点就要变成灰色;一旦某个节点已经遍历结束,就将其改为黑色。直接看看思路代码:
import java.util.ArrayList;
public class GC {
public enum Color {
WHITE,
GRAY,
BLACK;
}
public static class Node {
public int val;
public Color color = Color.WHITE;
public ArrayList<Node> next = new ArrayList<>();
public Node(int val) {
this.val = val;
}
}
public static void mark(Node[] nodes) {
System.out.print("遍历结果: [ ");
for (Node node: nodes) {
_mark(node);
}
System.out.println("]");
}
private static void _mark(Node node) {
// 已遍历结束的节点
if (node.color == Color.BLACK) {
return;
}
// 就是当前正在遍历的路径中的节点,说明有环了
if(node.color == Color.GRAY) {
return;
}
System.out.print(node.val + " ");
node.color = Color.GRAY;
for (Node next: node.next) {
_mark(next);
}
node.color = Color.BLACK;
}
}
接下来,假设我们的内存如下图所示,其中,箭头代表引用,红色代表该对象还不能回收(GC Roots 或者被 GC Roots 引用)。
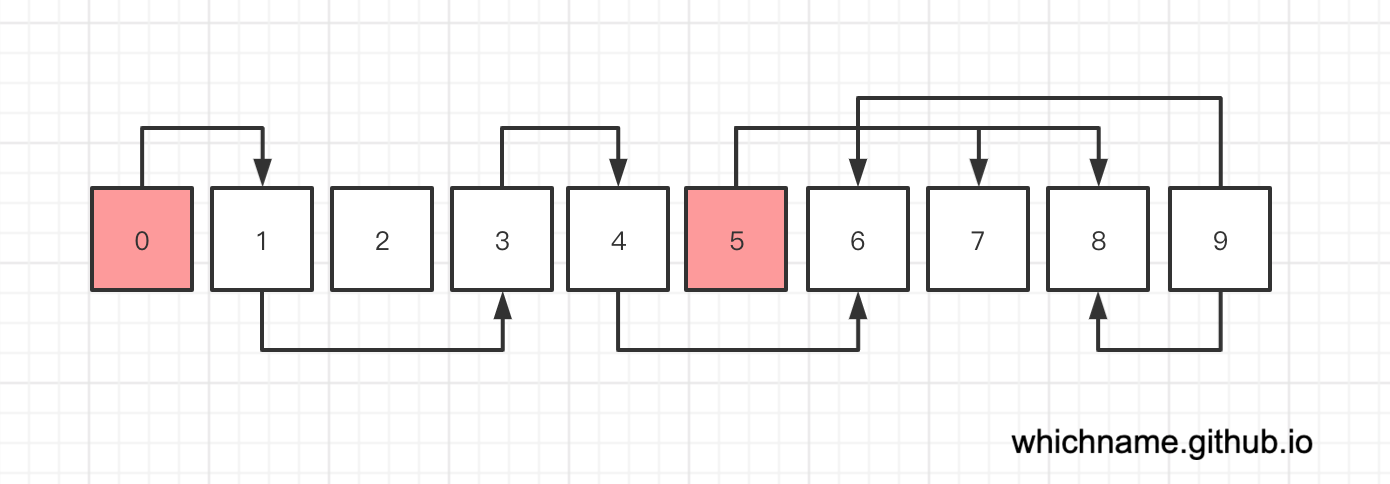
public static void main(String[] args) {
// 构造内存和引用关系
Node[] nodes = new Node[10];
for (int i = 0; i < 10; i++) {
nodes[i] = new Node(i);
}
nodes[0].next.add(nodes[1]);
nodes[1].next.add(nodes[3]);
nodes[3].next.add(nodes[4]);
nodes[4].next.add(nodes[6]);
nodes[5].next.add(nodes[7]);
nodes[5].next.add(nodes[8]);
nodes[9].next.add(nodes[6]);
nodes[9].next.add(nodes[8]);
// 不能被回收的对象
Node[] roots = new Node[] {
nodes[0],
nodes[5]
};
mark(roots);
}
运行结果为:遍历结果: [ 0 1 3 4 6 5 7 8 ] ,也就是说,2 和 9 已经没有被不可回收对象引用了,可以回收了。
并发标记问题
这里提一下为什么说三色标记法可以支持并发标记。在我们遍历的过程中,假如用户线程也同时在运行,那么肯定会有两种影响:
- 已经遍历过的引用关系被切断了,也就是说一个对象在我们扫描到他时引用关系还在,但是在并发扫描后续节点时引用关系却被切断了,那该对象就变成未及时回收的浮动垃圾;这种情况虽然不太好,但问题不大,可以接受。
- 在扫描过程中,用户线程增加了黑色对象到白色对象的引用,同时删除了所有灰色对象到该白色对象的引用;此时,该白色对象本不可被回收,但由于我们没有扫描到,导致该对象在标记阶段结束还是白色,从而被回收。这种情况问题就很严重了:本来有用的对象却被回收了。
关于问题 1 我们不再讨论,这里着重讨论一下问题 2。
网上大部分资料和《深入理解 JVM》一书中都提到,出现问题 2 的漏标情况,都有两个必要条件同时满足:
- 新增了黑色对象到白色对象的新引用;
- 清除了全部灰色对象对该白色对象的直接或间接引用;
条件 1 很好理解,因为我们遇到黑色对象是不会再继续扫描他的子节点的,这就会导致白色对象一直不会被标记到;
但是条件 2 要怎么理解呢?由条件 1 我们知道,我们到该漏标对象还是有可达引用路径的,因此我们可以通过黑色或灰色对象直接或间接引用到他;而黑色对象的所有子节点都已扫描完成,该漏标对象却是白色对象,说明他是被灰色对象直接或间接引用的;
知道了造成漏标问题的原因,我们也就有了对应的解决办法:
- 增量更新:破坏第一个条件,记录所有新增的引用关系,等并发扫描结束后再标记一遍这些新增的;
- 原始快照:破坏第二个条件,记录灰色到白色被删除的引用,等并发扫描结束后再标记一遍这些删除的;
解决了漏标的问题,我们就可以使用三色标记法来进行标记过程的并发了。
回收
标记过程解决的是怎么判断对象可不可以被回收的问题,接下来的回收阶段便是真正的内存回收。
内存回收有三种方式:清除、复制、整理。
清除
清除最简单,只需要在标记结束后,把不再使用的对象内存释放就可以了,且不涉及对象的移动,速度最快。但是清除法会带来一个不可避免的问题,那就是内存碎片化。
public static void sweep(Node[] nodes) {
for (int i = 0; i < nodes.length; i++) {
if (nodes[i].color == Color.WHITE) {
System.out.println("清除 [" + nodes[i].val + "] 节点");
nodes[i] = null;
}
}
System.out.print("清除后内存 [ ");
for (int i = 0; i < nodes.length; i++) {
System.out.print(nodes[i] != null ? nodes[i].val + " " : "null ");
}
System.out.println("]");
}
运行结果为:
清除 [2] 节点
清除 [9] 节点
清除后内存 [ 0 1 null 3 4 5 6 7 8 null ]
我们可以看到,此时的空闲内存不再连续,出现了碎片化。
复制
复制法就是将内存分为两块,分配内存时只在其中一块分配,回收时,将存活对象全部复制到另一块内存中。
public static void copy(Node[] nodes) {
Node[] newNodes = new Node[nodes.length];
int newIndex = 0;
for (int i = 0; i < nodes.length; i++) {
if (nodes[i].color == Color.BLACK) {
System.out.println("复制 [" + nodes[i].val + "] 节点");
newNodes[newIndex++] = nodes[i];
}
}
System.out.print("目标内存 [ ");
for (int i = 0; i < nodes.length; i++) {
System.out.print(newNodes[i] != null ? newNodes[i].val + " " : "null ");
}
System.out.println("]");
}
运行结果为:
复制 [0] 节点
复制 [1] 节点
复制 [3] 节点
复制 [4] 节点
复制 [5] 节点
复制 [6] 节点
复制 [7] 节点
复制 [8] 节点
目标内存 [ 0 1 3 4 5 6 7 8 null null ]
复制法比较适合存活对象少的情况,比如新生代;缺点就是,复制法要求有一块内存作为目标内存,也就是说虚拟机可使用的内存会比实际的内存要小。
整理
整理法跟复制法一样,也是将移动存活对象,不过整理法不需要专门的一块内存用于存放存活对象,而是直接覆盖前面的被回收对象,直接看下代码。
public static void compact(Node[] nodes) {
int dstIndex = 0;
for (int i = 0; i < nodes.length; i++) {
if (nodes[i] == null || nodes[i].color == Color.WHITE) {
nodes[i] = null;
continue;
}
if (dstIndex != i) {
nodes[dstIndex] = nodes[i];
nodes[i] = null;
}
dstIndex++;
}
System.out.print("整理后内存 [ ");
for (int i = 0; i < nodes.length; i++) {
System.out.print(nodes[i] != null ? nodes[i].val + " " : "null ");
}
System.out.println("]");
}
运行结果为:整理后内存 [ 0 1 3 4 5 6 7 8 null null ]
分代
标记过程解决了如何判断对象存活的问题,回收算法解决了如何回收垃圾对象的问题;而“分代收集”理论,可以说是基于整个堆内存层面的分类回收思想。分代收集是一种优化方法,并不是必须的,不过大多数虚拟机目前都使用了这个思想来进行 GC 的优化。
分代收集理论来源于两个假说:
- 弱分代假说:绝大多数对象都是朝生夕灭的
- 强分代假说:熬过越多次垃圾收集过程的对象越难于消亡
由此,大部分虚拟机将内存分为新生代和老年代,并对这两个区域分别采用不同的收集频率和策略来进行 GC。
- Minor GC:针对新生代的 GC,由于新生代存活对象较少,收集收益高,因此会相对频繁
- Major GC:针对老年代的 GC,只有 CMS 收集器会有单独收集老年代的行为
- Full GC:收集整个 Java 堆和方法区的 GC
通过分代思想,我们就可以多进行收益高的 Minor GC,实在没办法了再进行较为重量级的 Full GC,从而提高 GC 的整体性能。
为什么新生代要用复制
我们经常会看到说,虚拟机将内存分为新生代和老年代,其中新生代又分为一个 Eden 区和两个 Survivor 区,比例是 8:1:1。
实际上,前一个分类是基于分代收集理论,后一个,是因为新生代大多都采用了复制法,这是复制法的分区,两者不是同一逻辑。
这里就引出了一个问题,为什么新生代要用复制法?
我们知道,新生代的特点是存活对象相对较少,即使我们使用复制法,需要移动的对象也不会太多,性能可以接受;以此同时,我们还避免了清除法会引起的内存碎片化问题。
但是为什么不用整理法呢?我们从上面的算法可知,复制法时间复杂度为 O(n),空间复杂度也为 O(n),而整理法时间复杂度为 O(n),空间复杂度却可以做到 O(1),甚至对象的移动次数,都是小于等于复制法的。
这个问题当时困扰了我许久,其实答案也很简单,我们讨论复杂度的时候,只看到了“回收”阶段,而没有看到标记阶段。
要使用整理法有一个隐藏的条件,就是在移动对象时,我们需要知道目标位置在哪里;而要知道目标位置在哪,就要求先知道“前面的对象”是否可回收,只有当前面的对象可回收时,我们才能覆盖他。
而可达性分析法到达各存活对象在内存中是无序的,所以要使用整理法,我们就需要两次扫描:一次是可达性分析,一次是线性扫描移动对象。
复制法却没有这种要求,我们完全可以在可达性分析扫描时,直接将存活对象移动到另一块内存中。所以对新生代来说,使用复制法来进行回收更加合适。
触发时机
那么什么时候会触发 GC 呢?我们这里分情况讨论。
- Minor GC 的触发时机是当 Eden 区满了,没有足够空间可分配时。
- Full GC 的触发时机有四个:
System.gc()建议虚拟机进行 Full GC,但可能不生效- 老年代空间不足,无法容纳正常提升的对象、直接分配到老年代大对象、分配担保(survivor 存不下直接放入老年代)
- 通过 Minor GC 提升的平均大小大于老年代剩余空间
- 方法区空间不足
其中,CMS 这类并发收集器除了以上这些,还会定时去检查老年代的剩余空间,超过触发比例就会触发 Full GC;这是因为并发收集器在收集过程中,还需要预留内存给用户线程使用。
收集器
CMS
垃圾收集器有很多种,这里我们来说说 CMS,这算是最广为人知的收集器了。CMS 全称 Concurrent Mark Sweep,并发标记清除收集器。CMS 的收集过程也比较简单:
- 初始标记。仅标记 GC Roots 能直接关联到的对象
- 并发标记。就是三色标记法遍历图
- 重新标记。就是处理并发标记过程中,用户线程改动的引用关系,这里就是上面说的增量更新
- 并发清理
CMS 在收集时,必须预留部分内存给用户线程在并发阶段使用,要是预留的内存不够,就会出现并发失败 (Concurrent Mode Failure),导致进入完全 Stop The World 的 Full GC。此外,CMS 采用清除法,会导致内存碎片化,有可能会出现剩余内存不少,但没有足够大的连续空间,导致提前触发 Full GC。
G1、Shenanoah、ZGC
在 CMS 之后,业界又出现了一种新的收集思想:将一整块内存,划分为多块相同或不同的 Region,对这些 Region 进行局部的 GC。
基于 Region 的收集器,在 GC 时,会选择部分 Region,将其中的存活对象,复制到一个未使用的 Region 中,最后回收原来的 Region。
从整个堆的角度来看,这类回收算法采用的是整理法,GC 后的内存可以认为是规整的、无碎片的内存;而从 Region 的角度来看,采用的是复制法,可以在扫描的同时进行复制。
得益于此思想,这类收集器可以实现更加动态的、轻量的 GC,从而获得更好的性能。
感兴趣的同学建议阅读《深入理解 Java 虚拟机》一书。
Android 的 GC
DVM
DVM 使用的正是 CMS 收集器,有四种触发时机:
- GC_FOR_MALLOC:分配对象时内存不足,串行
- GC_CONCURRENT:已分配内存达到阈值时触发,并行
- GC_EXPLICIT:调用
System.gc、VMRuntime.gc触发,并行 - GC_BEFORE_OOM: OOM 前最后的努力,会清除软引用,串行
串行时,直接 Stop the world ,然后标记,最后 Resume ;
并行时,就是 CMS 的流程:先 Stop the world,扫描 GC Roots,然后 Resume,接着并发标记,然后 Stop the world ,标记增量部分,然后 Resume,并发清理。
ART
ART 包含两种 GC 方案,一种是跟 DVM 差不多的 CMS,第二种是并发复制 CC。
CMS
ART 的 CMS 跟 DVM 的其实差不多,区别在于:
- 总共包含了六种收集器:串行和并行各三个,分别是 Sticky、Partial 和 Full,其中 Sticky 只回收上次 GC 以来分配的对象(相当于新生代),Partial 只回收 Allocation Space,Full 还会回收 Zygote Space.
- DVM 上的两次 Stop the world 变成了一次,只保留了 Remark 部分的停顿。(看到有部分资料说 DVM 是三次 STW,我看老罗的分析只有两次)
- 引入了 Large Object Space 独立于堆,专门分配大对象
- 支持了 Compacting GC ,在应用处于后台、或者即将 OOM时,会进行堆压缩,非并发
CC (Concurrent Copy)
Android 8 新推出的基于 Region 的 GC,并发复制,也是默认的 GC 方案。
CC 采用的正是我们上面说到的基于 Region 的回收思想。它将内存划分为很多块 Region,GC 时,选择其中碎片化程度较高的 Region,将其中的存活对象复制到另一块空的 Region 中,然后释放原来的 Region。
在 Android 10 的时候,也支持了分代。